The Stability/Expressivity Duality: Architectural Trade-Offs in Modern LLMs
The Unseen Battle for Transformer Stability


The power of the Transformer architecture stems from its parallel processing capability, but the core engine—the self-attention mechanism’s dot product (Q . KT)—presents inherent numerical challenges that architects must carefully manage.
The Attention Logit Growth Problem
As model scale and layer count increase, the magnitudes of Query (Q) and Key (K) vectors can grow across layers. Their dot product generates attention scores that, if left unchecked, can lead to numerical instability. When these logits become very large, the softmax function saturates, causing gradients to diminish and making training unpredictable. This wastes GPU resources and introduces project risk. Normalization strategies serve as the primary architectural levers to mitigate this risk while balancing model expressivity and computational efficiency.
1. The Architectural Foundation: Pre-Normalization
The foundational architectural decision is how to structure the residual connection and where to place normalization layers—establishing the stability baseline that enables large-scale model development.

Enabling Depth and Scale
In modern deep architectures, the normalization step is applied before the attention and Feed-Forward Network (FFN) sub-layers, rather than after:
Why Pre-Norm Matters: By normalizing the input to every sub-layer, Pre-Norm ensures that signal magnitudes remain bounded regardless of model depth. This dramatically improves gradient flow consistency, enabling researchers to safely stack hundreds of layers—a prerequisite for modern LLM scale.
Post-Norm Limitations: The original Transformer architecture (Vaswani et al., 2017) placed normalization after the residual addition. While this approach can achieve slightly better performance at convergence for shallow models, it becomes increasingly difficult to train as depth increases. The unconstrained input to each sub-layer exacerbates gradient instability in very deep networks.
Verdict: Pre-Norm has become the de facto standard for deep LLM architectures (100+ layers), adopted by GPT-3, PaLM, LLaMA, and virtually all modern large-scale models. Post-Norm remains viable primarily for smaller or moderately-sized models where its representational advantages can be realized.
2. The Efficiency Optimization: RMSNorm
Once architectural stability is established via Pre-Norm, the next optimization focuses on maximizing hardware utilization and computational efficiency—where RMSNorm provides a strategic advantage.
Resource Efficiency Through Computational Simplification
Most modern high-performance LLMs (LLaMA, Mistral, Gemma) replace traditional LayerNorm with RMSNorm (Root Mean Square Normalization).
Traditional LayerNorm requires two statistical passes—calculating and subtracting the mean ($\mu$), then dividing by standard deviation (σ):
RMSNorm achieves empirically similar normalization while simplifying the operation by eliminating the mean-centering step:
The Efficiency Gain: This computational shortcut delivers measurable throughput improvements during both training and inference. Eliminating the mean calculation reduces memory bandwidth requirements and computational overhead, directly contributing to higher hardware utilization and lower operational cost per token.
Trade-off Considerations: Some research suggests LayerNorm may provide marginally better stability in specific edge cases due to its explicit mean-centering. However, empirical results from production models show RMSNorm performs comparably while offering 10-15% efficiency gains. The decision to use LayerNorm today is typically driven by legacy codebases rather than performance requirements.
3. The Advanced Constraint: QK-Norm (Stability vs. Expressivity)
While Pre-Norm + RMSNorm handles general layer-to-layer stability, QK-Norm is a specialized constraint applied specifically to the attention mechanism’s Query and Key vectors—not to the broader architecture.

The Attention-Specific Normalization
QK-Norm applies L2 normalization to Q and K vectors before computing attention scores:
This normalization projects vectors onto a unit hypersphere, mathematically reducing attention scores to the cosine similarity between Q and K.
The Expressivity Trade-off
What’s Lost: Traditional attention leverages both direction (semantic similarity) and magnitude (importance/certainty signals). QK-Norm eliminates the magnitude component, which can limit the model’s ability to:
Express varying degrees of confidence in attention patterns
Handle complex multimodal fusion tasks
Perform certain types of nuanced reasoning
What’s Gained: Guaranteed bounded attention logits provide exceptional numerical stability, making training more predictable and reducing the risk of attention pattern collapse in production environments.
Empirical Reality: Recent models demonstrate this isn’t a binary trade-off. Google’s Gemma 2 and Meta’s Llama 3.1 successfully employ QK-Norm while achieving state-of-the-art results, suggesting that at sufficient scale, the stability benefits can outweigh expressivity concerns for many tasks.
4. Strategic Decision Framework: Mapping Architecture to Objectives
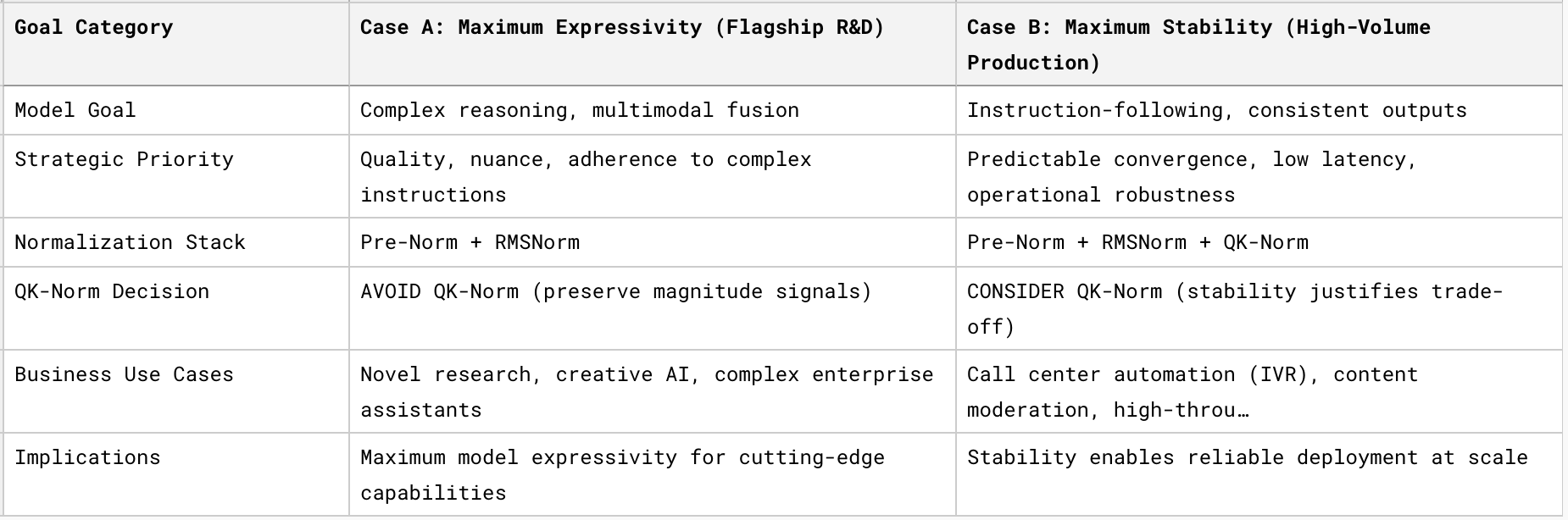
Decision Guidelines
Use Pre-Norm + RMSNorm when:
Building general-purpose foundation models
Prioritizing model capability and quality
Research and development workloads
Tasks requiring nuanced reasoning or multimodal understanding
Add QK-Norm (Pre-Norm + RMSNorm + QK-Norm) when:
Deploying high-throughput production systems
Stability and predictability are paramount
Training stability issues persist despite other interventions
Operating in resource-constrained environments where training failures are costly
Conclusion: Normalization as an Architectural Control Surface
The optimal default foundation for modern LLM development is Pre-Norm + RMSNorm. This combination provides essential stability for deep architectures and the computational efficiency needed for cost-effective training and inference—making it the lowest-risk starting point for most projects.
QK-Norm represents an additional stability constraint that should be viewed as a deliberate architectural choice: trading some degree of expressivity for guaranteed numerical stability. Deploy it when predictable training dynamics and operational reliability outweigh the need for maximum model capability.
Modern LLM architecture is fundamentally about managing trade-offs. Pre-Norm establishes depth capacity, RMSNorm optimizes efficiency, and QK-Norm provides a stability safety net. Understanding these components and their interactions ensures that architectural decisions align with project objectives—whether maximizing cutting-edge performance or guaranteeing bulletproof operational stability.
The key insight: Normalization isn’t just a technical detail—it’s a strategic dial that controls your architecture’s risk profile, computational efficiency, and ultimate capability ceiling. Choose wisely based on your mission-critical requirements.
References & Further Reading
Pre-Norm: “On Layer Normalization in the Transformer Architecture” (Xiong et al., 2020)
RMSNorm: “Root Mean Square Layer Normalization” (Zhang & Sennrich, 2019)
QK-Norm: Used in Gemma 2 (Google, 2024) and discussed in various architecture papers
Original Transformer: “Attention Is All You Need” (Vaswani et al., 2017)